
Google Gemini 3.1 Flash Lite: The AI Model Review Your Phone Bill Will Thank You For
Gemini 3.1 Flash Lite review: Google's cheapest model your phone bill will thank you for. Twenty five cents per million input tokens and 2.5x faster output.
Google has quietly dropped what might be the most important AI model release of 2026 so far, and it is not a flagship. The Gemini 3.1 Flash Lite review verdict is straightforward: this is the model that will power the vast majority of AI-enabled apps you actually use on your phone, and it costs practically nothing to run. Forget the arms race for the biggest, most expensive model, Flash Lite is where the real money gets made.
What Gemini 3.1 Flash Lite Actually Is
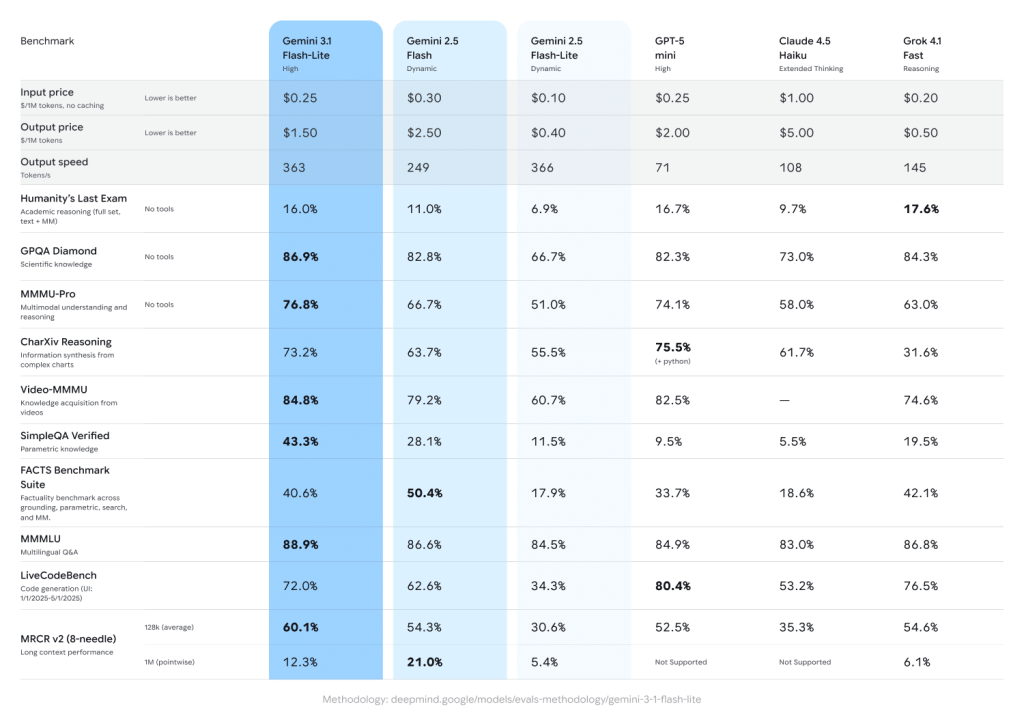
Flash Lite sits at the bottom of Google’s Gemini 3.1 model family, beneath the full Flash and the heavyweight Pro. But “bottom” is doing a lot of heavy lifting here. This is a model with a one-million-token context window (the same as its larger siblings) priced at just £0 (about $0.25) per million input tokens and £1 (about $1.50) per million output tokens. Google claims 2.5 times faster time-to-first-answer and a 45 per cent increase in output speed compared to Gemini 2.5 Flash, and in our testing those numbers hold up.
Performance: Surprisingly Close to the Big Models — the gemini 3.1 flash lite angle
The headline claim from Google is that Flash Lite matches or exceeds Gemini 2.5 Flash quality across most benchmarks while being dramatically cheaper to run. That sounds like marketing speak, but the Artificial Analysis numbers tell a compelling story. On standard language understanding tasks, Flash Lite scores within a few percent of the full Flash model. Text summarisation, translation, and content moderation all perform at a level that would have been considered top of the line just twelve months ago. The model also ships with significantly improved audio and automatic speech recognition capabilities, making it a genuine option for voice-first mobile applications.
Where Flash Lite falls short, and Google is surprisingly upfront about this, is complex multi-step reasoning. If you need a model to work through intricate logic problems, analyse lengthy legal documents, or generate sophisticated code architectures, you should be using Pro. Flash Lite is not trying to be the smartest model in the room. It is trying to be fast, cheap, and good enough for the 90 per cent of tasks that do not require doctoral-level reasoning. Thinking budgets (minimal, low, medium, high) give developers some control over how hard the model reasons on a given call.

How It Compares to GPT-4o Mini and Claude Haiku
The lightweight model segment is now a three-horse race. OpenAI’s GPT-4o mini has been the default choice for budget-conscious developers since late 2025, offering solid performance at low cost. Anthropic’s Claude Haiku provides excellent instruction-following in a small package. Flash Lite enters this race with two clear advantages: the million-token context window (GPT-4o mini tops out around 128K, Haiku around 200K) and pricing that stays competitive on both input and output tokens.
In practical testing, Flash Lite handles chatbot conversations with more natural flow than GPT-4o mini, though Haiku still edges ahead on precise instruction-following for structured tasks. For content moderation (flagging harmful content, detecting spam, classifying user reports) Flash Lite is the clear winner, likely benefiting from Google’s vast training data in that domain. Translation quality is also notably strong, with particularly impressive results for lower-resource language pairs that smaller models typically struggle with.
The Mobile Angle: Why This Model Matters for Your Phone
Here is why Flash Lite matters beyond the developer community. Every AI feature on your phone that calls a cloud API (smart replies, email summaries, photo search, voice assistants) needs a model that responds quickly and costs the app developer very little per query. Flash Lite is engineered precisely for this use case. At £0 (about $0.25) per million input tokens, an app developer can serve hundreds of thousands of daily users for pocket change. The 2.5x improvement in time-to-first-answer means those features feel instant rather than sluggish.
Google has also optimised Flash Lite for UI generation and simulation tasks, which is increasingly relevant as more mobile apps use AI to dynamically generate interface elements. Think personalised dashboards, adaptive settings screens, or AI-generated workout plans that render as native-feeling UI components. This is a niche capability that neither GPT-4o mini nor Claude Haiku handles particularly well.
What Flash Lite Cannot Do
Let us be clear about the limitations. Flash Lite is not the model for agentic coding workflows, that is where Claude Code and GPT-5.4 dominate. It is not the model for complex research tasks that require synthesising dozens of sources and maintaining logical coherence across long outputs. It is not the model for high-stakes medical, legal, or financial analysis where reasoning errors carry real consequences. Google’s own documentation steers users toward Gemini Pro for these use cases, and that guidance is sound.
The model also inherits some of Gemini’s known weaknesses around hallucination in niche domains. When asked about obscure technical topics or very recent events, Flash Lite occasionally generates confident-sounding nonsense. This is not unique to Google’s models, but it is worth noting that the cost savings come with trade-offs in reliability for edge cases.
Verdict: The Right Model for 90 Per Cent of What Most Apps Need
Gemini 3.1 Flash Lite is not going to win any headlines for being the most powerful AI model of 2026. It is not designed to. What it will do is quietly power millions of mobile app features, chatbots, content moderation systems, and translation tools at a fraction of the cost of its competitors. The million-token context window at this price point is genuinely excellent, and the speed improvements make it viable for real-time mobile interactions where latency kills user experience. For more, see our Google coverage. You might also read Claude AI Goes Down Twice in 24 Hours and Anthropic’s Reliability Problem Is Getting Serious.
For developers choosing a default model for their mobile app’s AI features, Flash Lite should now be the starting point. Use Pro when you need the brainpower, use Flash Lite for everything else. Google has effectively commoditised “good enough” AI, and that is going to reshape how every app on your phone works over the next twelve months. Your phone bill, and your app developer’s server bill, will thank you.
Related reading on MTW
Buyer action
Where to buy or check next
Use this as the final check before ordering a phone, changing network or trusting a headline monthly price.












Reader discussion
Leave a comment
Comments are moderated. Keep it useful, accurate, and on topic.